
[RAG 도전기] PDF Document Loader 비교해보기
안녕하세요 마개입니다.
RAG를 개발하면서 얻는 지식을 정리해봅니다. 이번에는 Document Loader 종류 중 PDF를 대상으로 한 Loader 종류입니다.

PyPDF
PyPDF Document Loader는 PyPDF 패키지를 이용하는 방법입니다. PyPDF는 오픈 소스 라이브러리로 PDF와 관련된 많은 작업을 처리할 수 있습니다. 예를 들어, PDF 페이지 추가, 회전, 자르기 등 여러 기능을 제공합니다. 이 Document Loader의 주요 기능은 PDF 파일을 읽고 콘텐츠를 추출하는 작업입니다. 그외 비밀번호가 있는 파일을 다루거나 이미지를 추출하는 등의 기능을 제공합니다.
1
$ pip install langchain-community pypdf
파이썬에서 langchain과 함께 PyPDFLoader를 이용할 수 있습니다.
PyMuPDF
PyMuPDF Document Loader는 PyMuPDF 패키지를 이용하는 방법입니다. 이 PyMuPDF도 PDF 파일에서 데이터를 추출하고 분석하고 조작하는데 사용되는 라이브러리입니다. PyMuPDF는 다른 PDF 패키지인 PyPDF2나 pdfplumber, pdfminer와는 다르게 PDF뿐만 아니라 이미지, 텍스트, 워드 등 여러 플랫폼에서도 추출할 수 있다는 장점이 있습니다.
- 참고 링크 : PyMuPDF
1
$ pip install langchain-community pymupdf
이 PyMuPDF도 마찬가지로 langchain과 함께 PyMuPDFLoader를 이용할 수 있습니다.
UnstructuredPDF
UnstructuredPDF Document Loader는 unstructed 패키지를 이용하는 방법입니다. 이 패키지는 PDF 파일 내의 텍스트 조각(chunk)를 서로 다른 “elements”로 생성하고 이러한 elements를 결합하여 하나의 텍스트 데이터로 반환합니다.
1
$ pip install unstructured unstructured-inference
UnstructuredPDFLoader를 이용하여 페이지를 로드하는 작업을 진행합니다. 여기서 mode 파라미터를 설정할 수 있는데 single이면 하나의 페이지로, elements면 각 조각을 별도로 분리합니다.
그리고 이 Loader는 OCR 기술을 이용하기 때문에 텍스트가 아니라 이미지로 되어있는 PDF를 loading하기에 좋은 Loader입니다. 여기에는 strategy 옵션이 있는데 이 값으로는 “fast” 또는 “hi-res”를 입력할 수 있습니다.
PyPDFium2
PyPDFium2 Document Loader는 pypdfium2 패키지를 이용하는 방법입니다.
1
$ pip install -U langchain-community pypdfium2
PyPDFium2Loader를 이용하여 페이지를 로드하는 작업을 진행합니다.
PDFPlumber
PDFPlumber Document Loader는 PyMuPDF와 마찬가지로 PDF에 대한 상세한 메타데이터와 페이지 정보가 나옵니다. 그리고 페이지당 하나의 Document 객체를 생성합니다.
1
$ pip install -qU langchain_community
PDFPlumberLoader를 이용하여 해당 PDFPlumber 기술을 이용할 수 있습니다.
각 Loader 비교
각 Loader의 성능을 확인해보니 위해 동일한 PDF 파일을 Load하여 첫번쨰 페이지의 내용을 텍스트 파일로 저장하고 결과를 비교해봤습니다. 여기서는 두 개의 PDF 파일을 진행해봤습니다.
Document #1
첫번째 PDF를 보면 다음과 같습니다.
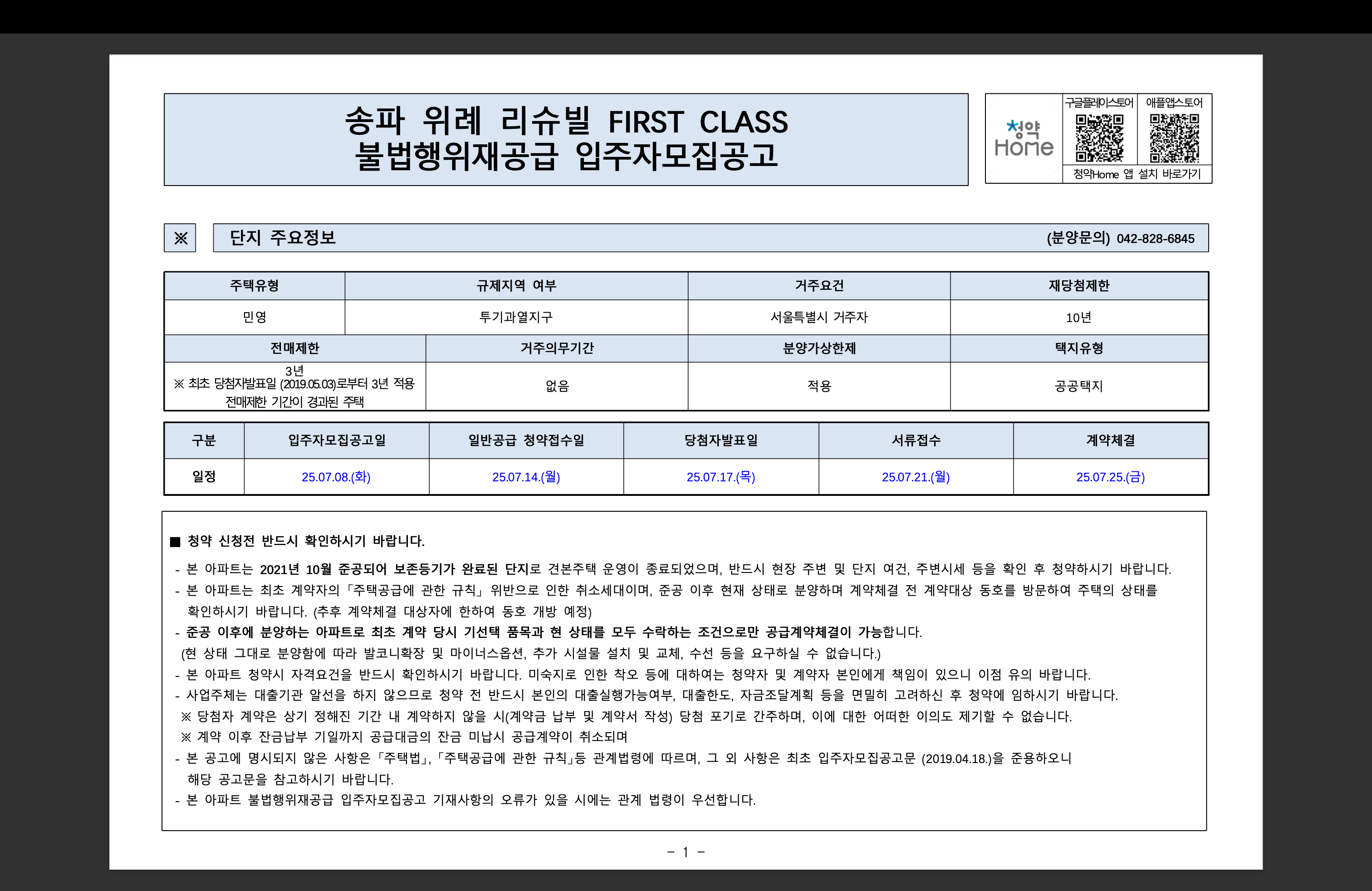 PDF 파일을 보면 테이블과 함꼐 텍스트가 있는 구조로 되어있습니다. 이 PDF를 여러 Loader로 확인해봅니다.
PDF 파일을 보면 테이블과 함꼐 텍스트가 있는 구조로 되어있습니다. 이 PDF를 여러 Loader로 확인해봅니다.
PyPDF
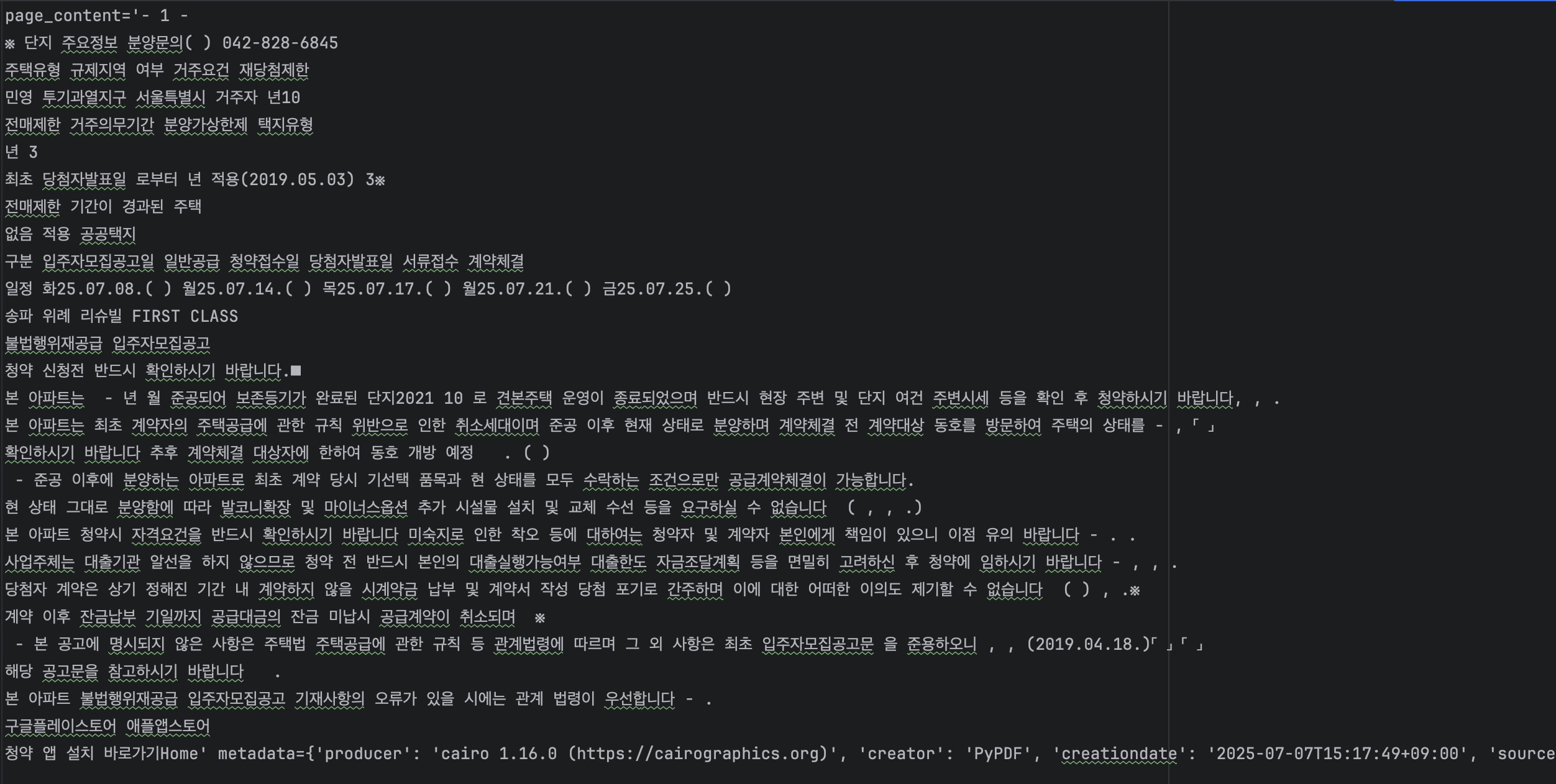
첫 번째로 PyPDF의 결과입니다. 맨 위의 타이틀의 경우 맨 처음에 나오는 것이 아니라 테이블 구조와 하단에 텍스트 구조 사이에 있는 것을 볼 수 있습니다. 테이블의 경우 행 순서대로 1행의 내용들이 차례대로 나오고 그 다음 행의 내용이 나오는 순서로 진행되고 있는 것을 볼 수 있습니다. 테이블에서 특이한 부분은 “(화)”와 같이 괄호 안에 요일이 있는데 여기서 요일은 날짜의 맨 앞으로 나오고 괄호 안에는 빈칸이 있는 것을 볼 수 있습니다.
테이블 아래에 텍스트 구조도 결과를 확인해보겠습니다. 여기에도 특징들을 잡아보면 일단 특수문자의 경우 맨 뒤에 나온다는 점입니다. “-“, “,”, “.”과 같은 특수 문자들은 거의 맨뒤로 가있고 일부만 본 위치에 있거나 다른 위치에 있는 것을 볼 수 있습니다. 그리고 일부 숫자도 제대로 된 위치에 있지 않은 것을 볼 수 있습니다.
PyMuPDF

 두 번째로
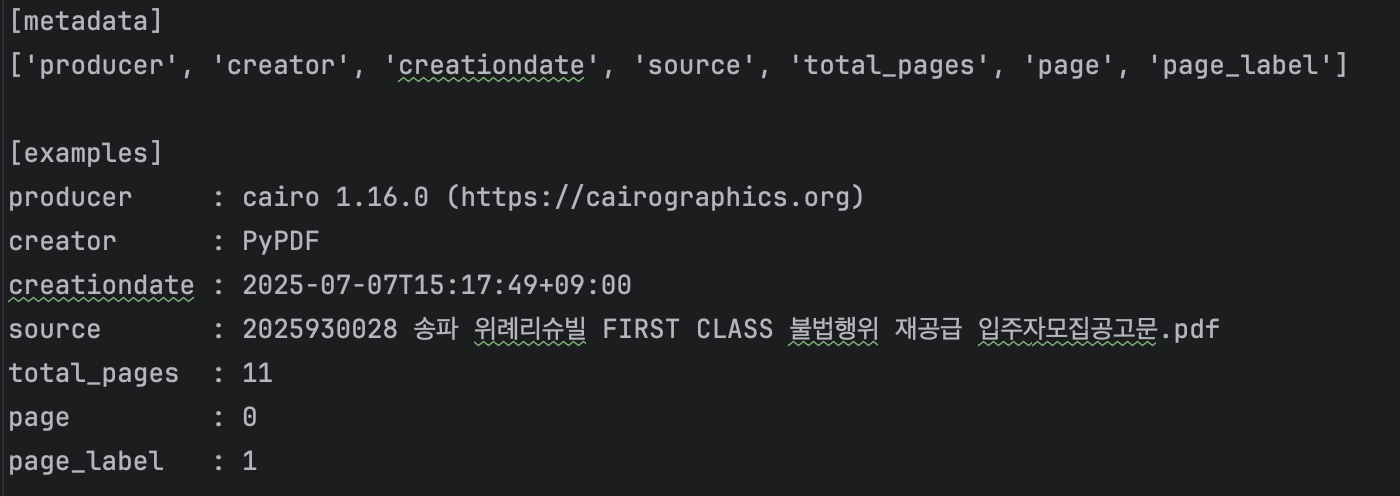
두 번째로 PyMuPDF의 결과입니다. 이번에는 결과를 보면 알 수 있듯이 단어별 또는 구역별로 구분을 해놓은 모습을 볼 수 있습니다. PyPDF와 마찬가지로 숫자가 뒤로 물리는 경우도 있고 특수문자도 밀리는 것을 볼 수 있습니다.
메타 데이터의 경우 여러 Key가 있는 것을 볼 수 있지만 Value는 없는 것을 볼 수 있습니다.
UnstructuredPDF
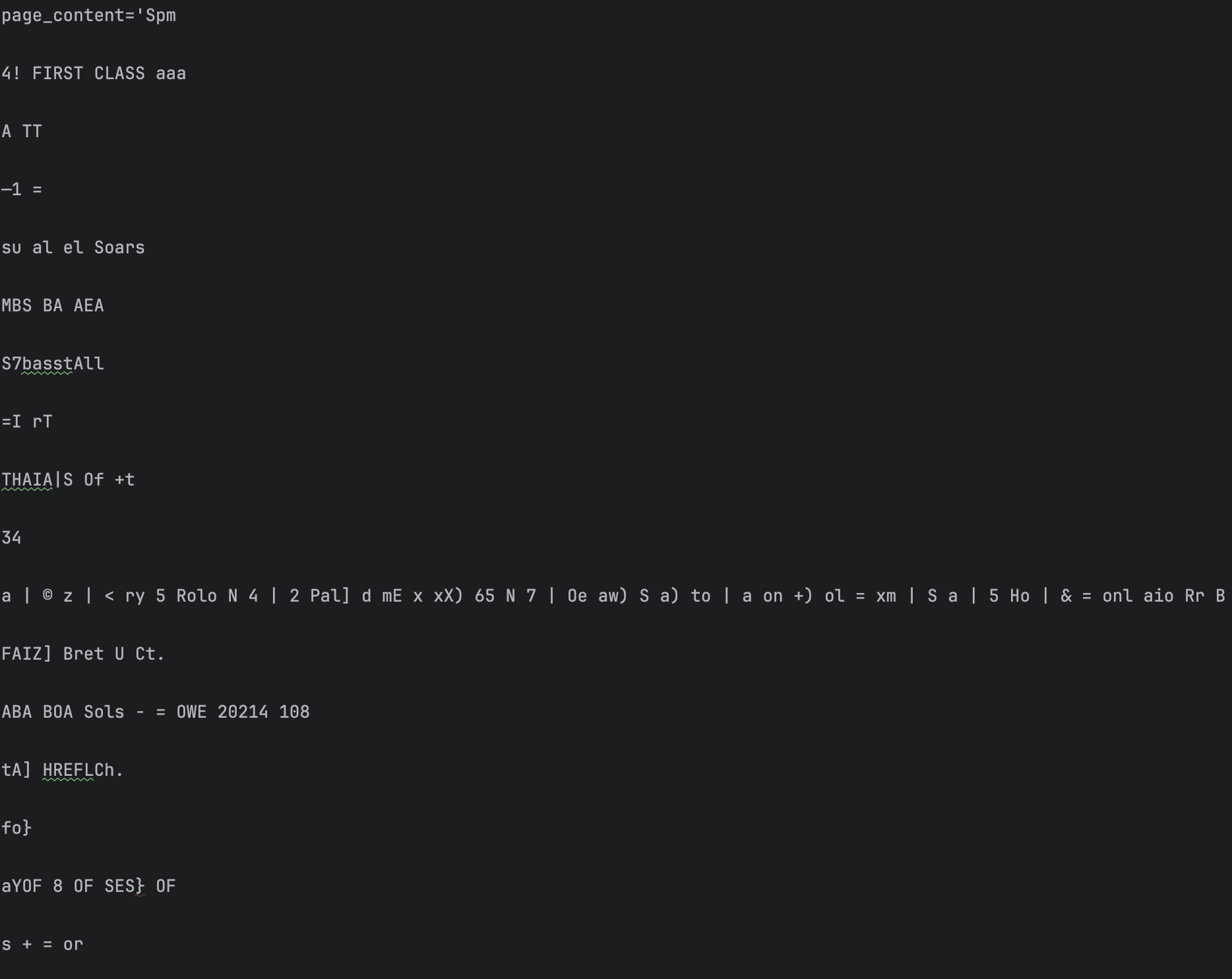

UnstructuredPDF는 OCR 기술을 이용하여 PDF 내용을 load하는데 그렇기 때문에 결과가 제대로 나오지 않은 것을 볼 수 있습니다. 메타데이터는 “source”만 있어 다른 정보는 없는 것을 볼 수 있습니다.
PyPDFium2
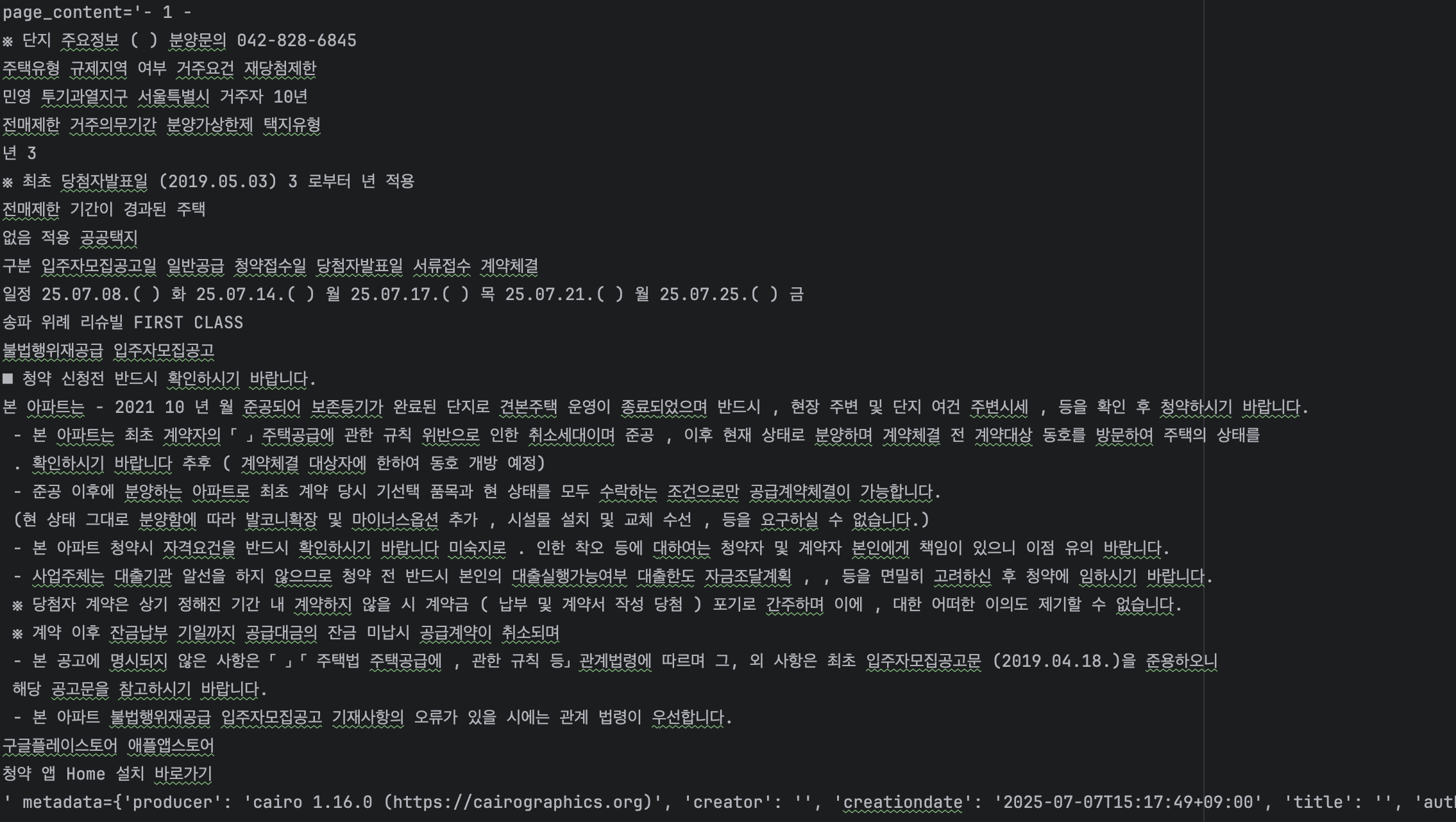
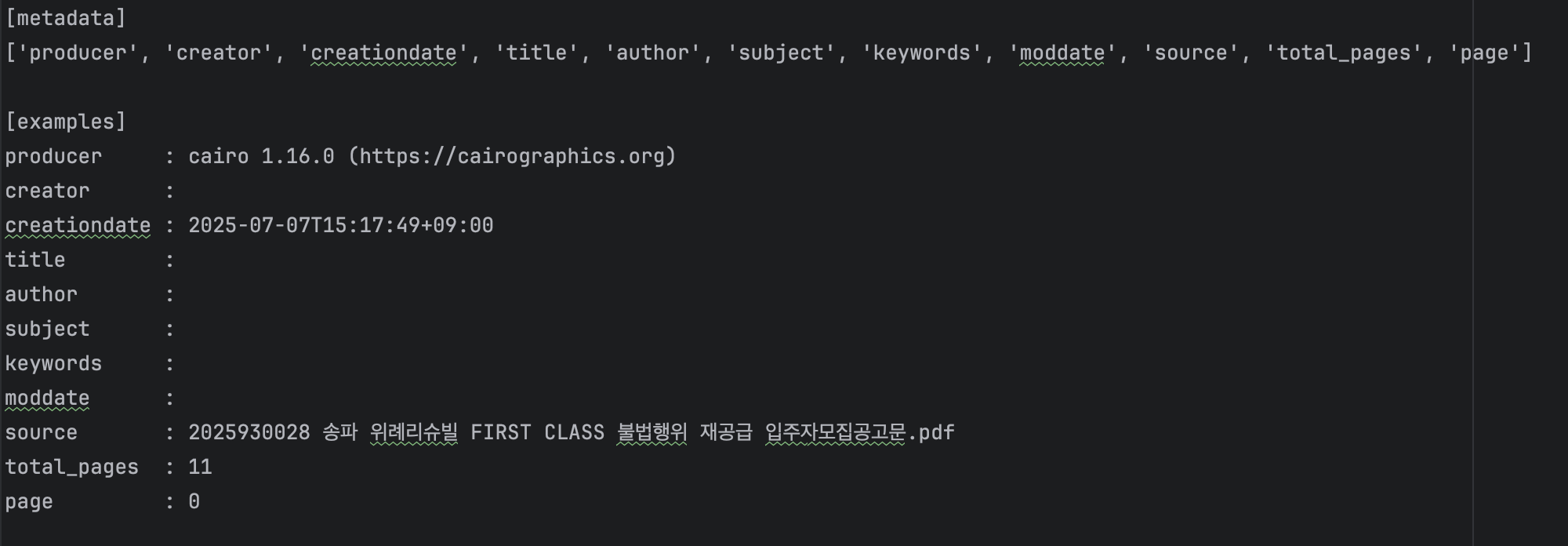
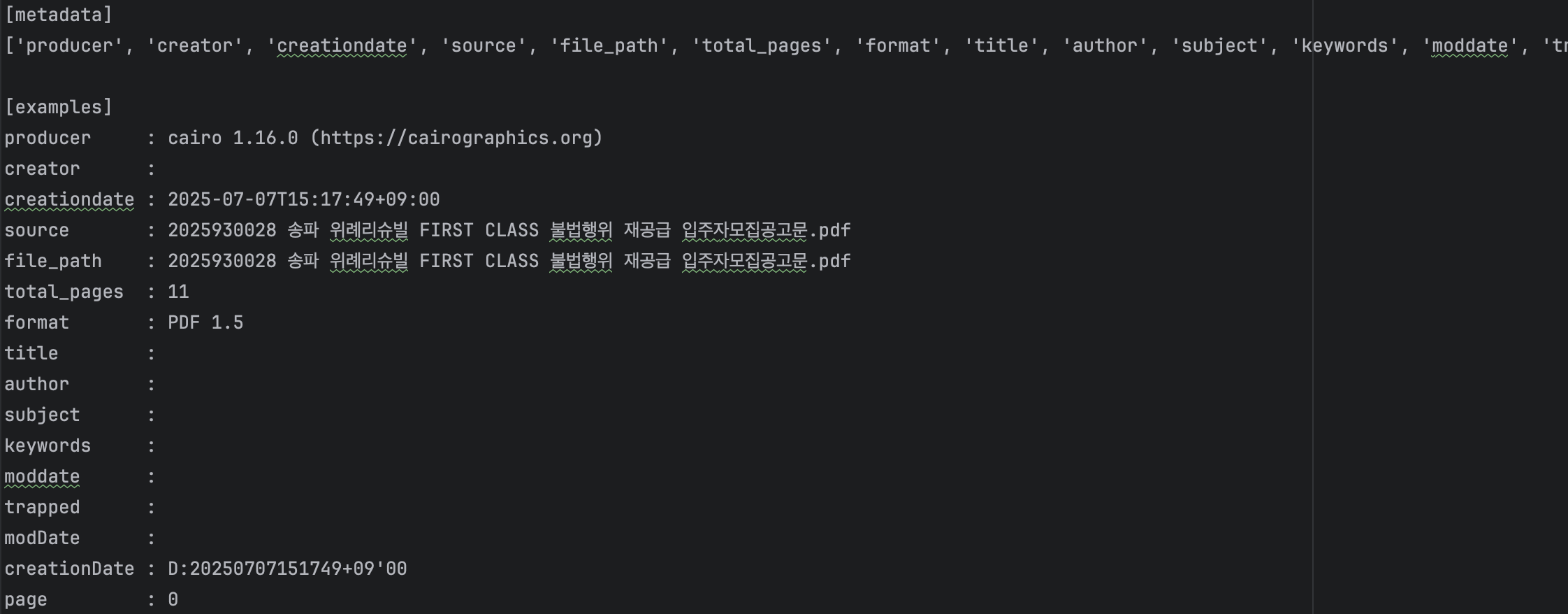
PyPDFium2는 지금까지 본 데이터 중에 가장 좋아보이는 결과인 것 같습니다. PyPDF도 좋은 결과를 보였는데 그것과 눈에 띄게 다른 점은 특수문자까지도 순서에 맞게 (PyPDF에 비해 상대적으로) 나왔습니다. 이것이 다른 점이라고 보입니다.
메타데이터도 여러 Key를 가져오는데 값은 전부는 아니지만 어느 정도 있는 것으로 보입니다.
PDFPlumber
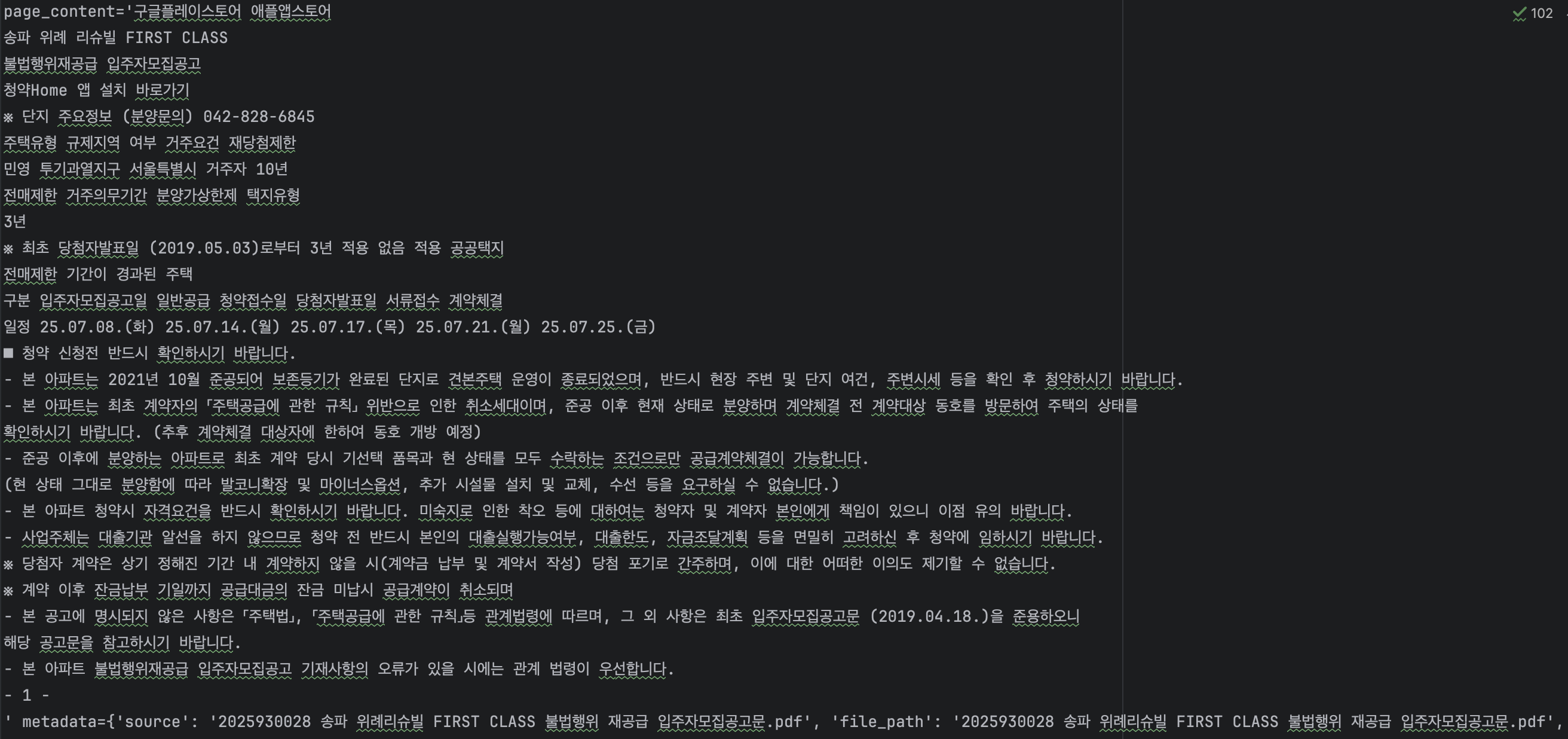
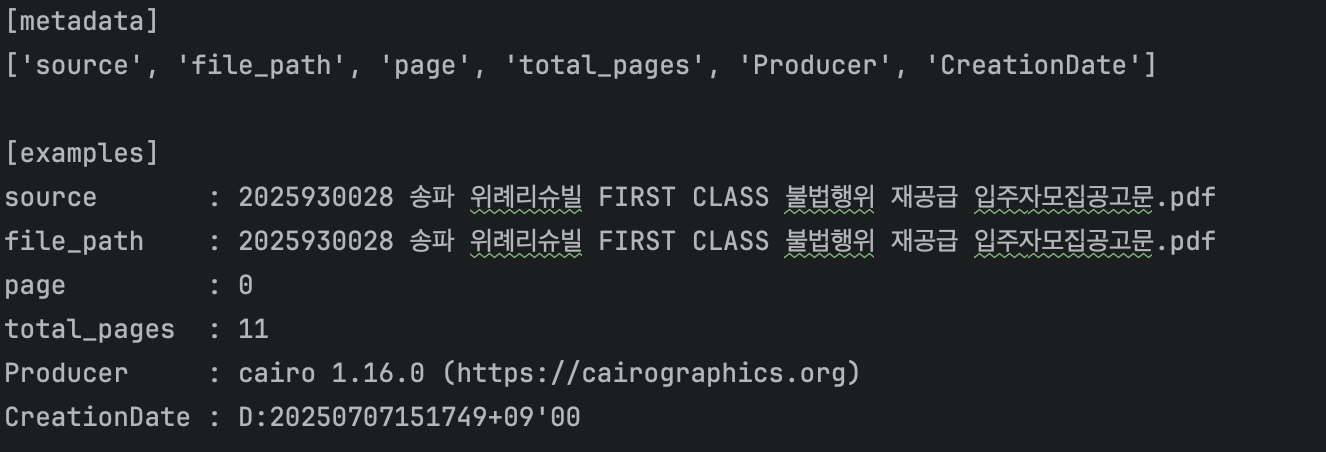 마지막으로
마지막으로 PDFPlumber입니다. 이 방법이 위의 PyPDFium2보다 더 좋아보이는 결과를 보이고 있습니다. 제목에서부터 한 줄씩 내려오면서 나타내고 있고 기존에 다른 것들과 두드러지게 차이나는 것은 괄호 안에 글자가 그대로 담겨있다는 것입니다. 위에서 봤던 다른 것들은 전부 괄호 안에 글자가 없고 뒤로 빠진 상태였다면 이 PDFPlumber는 제대로 담겨있는 것을 볼 수 있죠
메타데이터 안에서 Key는 많지는 않지만 전부 Value를 가지고 있는 것을 볼 수 있습니다. source나 total_pages나 전부 맞는 것을 알 수가 있죠