
[RAG 도전기] 벡터 데이터베이스란 (Vector Database)
안녕하세요 마개입니다.
RAG를 개발하면서 얻는 지식을 정리해봅니다. 이번에는 벡터 (Vector) 데이터베이스입니다.
벡터 데이터베이스란 (Vector Database)
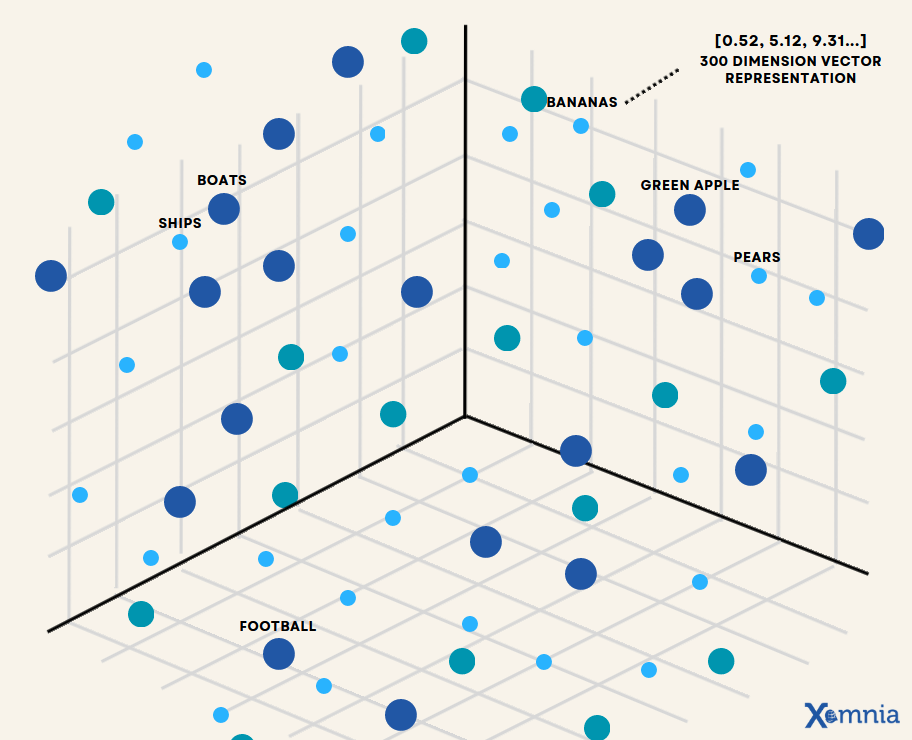
벡터(Vector) 데이터베이스는 벡터 형식의 데이터를 저장, 쿼리하고 분석하는데 특화된 데이터베이스입니다. 이 벡터 형식의 데이터는 우리가 일상 생활에서 사용하는 언어와 같은 복잡하고 긴 데이터를 0과 1로 이루어진 행렬로 표시한, 즉 벡터로 변환된 것을 말하고 이러한 자연어를 컴퓨터가 이해할 수 있는 형태인 벡터로 전환하는 과정을 벡터화(Vectorization)라고 합니다.
임베딩 (Embedding)
벡터화를 통해서 자연어를 컴퓨터가 이해하는 벡터로 전환을 하는데 자연어는 복잡하고 데이터 간에 여러 의미가 있기 때문에 고차원 벡터를 이용해서 컴퓨터를 이해시켜야 합니다. 이때 고차원 벡터를 생성하는 과정이 임베딩(Embedding)입니다.
이렇게 임베딩된 고차원 벡터들을 저장하고 효율적으로 검색할 수 있게 도와주는 것이 바로 벡터 데이터베이스 입니다.
기존 데이터베이스와의 차이
기존의 관계형 데이터베이스(RDB)의 경우 행(Row)과 열(Column)로 이루어진 2차원 테이블로 데이터가 구성되어 있습니다. 데이터를 정형화된 형식으로 저장하고 SQL을 이용하여 데이터를 다루는 형태입니다.
반면에 벡터 데이터베이스는 고차원 벡터 데이터를 처리하는데 최적화된 데이터베이스로 유사도 검색을 위해 설계되었습니다. 벡터 데이터는 2차원을 넘어 고차원 공간에서 데이터를 표현하게 되고 모델링하게 됩니다. 관계형 데이터베이스에서는 SQL을 이용하여 데이터를 조회하고 다루지만 벡터 데이터베이스에서는 유사도 (Similarity)를 기반으로 데이터를 조회합니다. 이렇게 고차원의 데이터를 다루기 때문에 언어나 이미지 데이터를 저장하는데 좋다고 볼 수 있습니다.
주요 벡터 데이터베이스
현재 여러 벡터 데이터베이스를 제공하고 있는데 오픈소스도 있고 오픈소스가 아닌 것도 있습니다.
- FAISS :
FAISS는 페이스북에서 개발한 오픈소스 벡터 데이터베이스로 고차원 벡터 데이터를 효율적으로 저장, 검색할 수 있으며, 대규모 벡터 데이터셋을 지원합니다. 또한, GPU를 활용하여 병렬 처리 및 속도 향상을 제공합니다. - Elasticsearch : Elasticsearch는 검색 엔진으로 유명한 오픈 소스입니다. 검색 엔진으로 유명한데 기존 기능을 그대로 유지하면서 벡터 검색 기능도 추가되어 고차원 벡터 데이터를 처리할 수 있게 되었습니다. 그렇기 때문에 기존의 방식과 벡터 데이터베이스를 합친 하이브리드 검색을 구현할 수 있다는 것이 장점입니다. 또한, 분산형 아키텍처를 가지고 있다는 것도 장점입니다.
- ChromaDB : 파이썬 환경에서 사용을 염두에 두고 설계된 벡터 데이터베이스로 간단하고 직관적인 인터페이스를 제공합니다. 또한, 동적 인베딩 방식으로 실시간으로 벡터를 업데이트하고 검색할 수 있다는 것이 장점입니다. 벡터 데이터베이스에 특화되어 있어 속도는 좋지만 대규모 데이터셋을 처리하는데 한계가 있을 수 있습니다.